
 SEO优化
SEO优化  搜索引擎SEO
搜索引擎SEO 北京搜索优化
Google 的自动抓取工具支持 REP(robots 协议)。这意味着,在抓取某一网站之前,Google 抓取工具会下载并解析该网站的 robots.txt 文件,以提取关于网站中哪些部分可以被抓取的信息。REP 不适用于由用户控制的 Google 抓取工具(例如 Feed 订阅),也不适用于用来提高用户安全性的抓取工具(例如恶意软件分析)。
本文介绍了 Google 对 REP 的解读。有关原始草稿标准的信息,请查看 IETF Data Tracker。 如果您是首次接触 robots.txt,请先阅读我们的 robots.txt 简介。您还可以找到关于创建 robots.txt 文件的提示,以及一个详尽的常见问题解答列表。
什么是 robots.txt 文件
如果您不希望抓取工具访问您网站中的部分内容,可以创建包含相应规则的 robots.txt 文件。robots.txt 文件是一个简单的文本文件,其中包含关于哪些抓取工具可以访问网站的哪些部分的规则。例如,example.com 的 robots.txt 文件可能如下所示:
# This robots.txt file controls crawling of URLs under https://example.com.
# All crawlers are disallowed to crawl files in the "includes" directory, such
# as .css, .js, but Googlebot needs them for rendering, so Googlebot is allowed
# to crawl them.
User-agent: *
Disallow: /includes/
User-agent: Googlebot
Allow: /includes/
Sitemap: https://example.com/sitemap.xml
文件位置和有效范围
您必须将 robots.txt 文件放在网站的顶级目录中,并为其使用支持的协议。就 Google 搜索而言,支持的协议包括 HTTP、HTTPS 和 FTP。使用 HTTP 和 HTTPS 协议时,抓取工具会使用 HTTP 无条件 GET 请求来提取 robots.txt 文件;使用 FTP 时,抓取工具会使用标准 RETR (RETRIEVE) 命令,并采用匿名登录方式。
robots.txt 文件中列出的规则只适用于该文件所在的主机、协议和端口号。
和其他网址一样,robots.txt 文件的网址也区分大小写。
有效 robots.txt 网址的示例
下表列出了 robots.txt 网址及其适用的网址路径的示例。
robots.txt 网址示例 http://example.com/robots.txt 适用于:http://example.com/
http://example.com/folder/file
不适用于:
http://other.example.com/
https://example.com/
http://example.com:8181/
这属于一般情况。该网址对其他子网域、协议或端口号来说无效。对同一个主机、协议和端口号上的所有子目录中的所有文件有效。 http://www.example.com/robots.txt 适用于: http://www.example.com/
不适用于:
http://example.com/
http://shop.www.example.com/
http://www.shop.example.com/
子网域上的 robots.txt 只对该子网域有效。 http://example.com/folder/robots.txt 不是有效的 robots.txt 文件。抓取工具不会检查子目录中的 robots.txt 文件。 http://www.ex?mple.com/robots.txt 适用于:
http://www.ex?mple.com/
http://xn--exmple-cua.com/
不适用于:
http://www.example.com/
IDN 等同于其对应的 Punycode 版本。另请参阅 RFC 3492。 ftp://example.com/robots.txt 适用于: ftp://example.com/
不适用于: http://example.com/ http://212.96.82.21/robots.txt 适用于: http://212.96.82.21/
不适用于: http://example.com/(即使托管在 212.96.82.21 上)
以 IP 地址作为主机名的 robots.txt 只在抓取作为主机名的该 IP 地址时有效。该 robots.txt 文件并不会自动对该 IP 地址上托管的所有网站有效,但该文件可能是共享的,在此情况下,它也可以在共享主机名下使用。 http://example.com/robots.txt 适用于:
http://example.com:80/
http://example.com/
不适用于:
http://example.com:81/
标准端口号(HTTP 为 80,HTTPS 为 443,FTP 为 21)等同于其默认的主机名。 http://example.com:8181/robots.txt 适用于: http://example.com:8181/
不适用于: http://example.com/
非标准端口号上的 robots.txt 文件只对通过这些端口号提供的内容有效。
错误处理和 HTTP 状态代码
在请求 robots.txt 文件时,服务器响应的 HTTP 状态代码会影响 Google 抓取工具使用 robots.txt 文件的方式。下表总结了 Googlebot 针对各种 HTTP 状态代码处理 robots.txt 文件的方式。
错误处理和 HTTP 状态代码 2xx(成功) 表示成功的 HTTP 状态代码会提示 Google 抓取工具处理服务器提供的 robots.txt 文件。 3xx(重定向) Google 会按照 RFC 1945 的规定跟踪至少五次重定向,然后便会停止,并将其作为 robots.txt 的 404 错误来处理。这也适用于重定向链中任何被禁止访问的网址,因为抓取工具会由于重定向而无法提取规则。Google 不会跟踪 robots.txt 文件中的逻辑重定向(框架、Javascript 或元刷新型重定向)。 4xx(客户端错误) Google 抓取工具会将所有 4xx 错误解读为网站不存在有效的 robots.txt 文件,这意味着抓取将不受限制。
这包括 401 (unauthorized) 和 403 (forbidden) HTTP 状态代码。 5xx(服务器错误) 由于服务器无法对 Google 的 robots.txt 请求提供明确响应,因此 Google 会暂时将服务器错误解读为网站完全禁止访问。Google 会尝试抓取 robots.txt 文件,直到获得非服务器错误的 HTTP 状态代码。503 (service unavailable) 错误会导致非常频繁的重试操作。如果连续 30 天以上无法访问 robots.txt,Google 会使用该 robots.txt 的最后一个缓存副本。如果没有缓存副本,Google 会假定没有任何抓取限制。
如果您需要暂停抓取,建议为网站上的每个网址提供 503 HTTP 状态代码。
如果我们能够确定,某网站因为配置不正确而在缺少网页时返回 5xx 而不是 404 状态代码,就会将该网站的 5xx 错误作为 404 错误处理。例如,如果返回 5xx 状态代码的网页上的错误消息为"找不到网页",我们会将该状态代码解释为 404 (not found)。 其他错误 对于因 DNS 或网络问题(例如超时、响应无效、重置或断开连接、HTTP 组块错误等)而无法抓取的 robots.txt 文件,系统在处理时会将其视为服务器错误。
缓存
Google 通常会将 robots.txt 文件的内容最多缓存 24 小时,但在无法刷新缓存版本的情况下(例如出现超时或 5xx 错误时),缓存时间可能会延长。已缓存的响应可由各种不同的抓取工具共享。Google 会根据 max-age Cache-Control HTTP 标头来延长或缩短缓存生命周期。
文件格式
robots.txt 文件必须是采用 UTF-8 编码的纯文本文件,且各行代码必须以 CR、CR/LF 或 LF 分隔。
Google 会忽略 robots.txt 文件中的无效行,包括 robots.txt 文件开头处的 Unicode 字节顺序标记 (BOM),并且只使用有效行。例如,如果下载的内容是 Html 格式而非 robots.txt 规则,Google 会尝试解析内容并提取规则,而忽略其他所有内容。
同样,如果 robots.txt 文件的字符编码不是 UTF-8,Google 可能会忽略不属于 UTF-8 范围的字符,从而可能会导致 robots.txt 规则无效。
Google 目前强制执行的 robots.txt 文件大小限制是 500 KiB,并忽略超过该上限的内容。您可以通过整合会导致 robots.txt 文件过大的指令来减小 robots.txt 文件的大小。例如,将已排除的内容放在一个单独的目录中。
语法
有效的 robots.txt 行由一个字段、一个冒号和一个值组成。可以选择是否使用空格,但建议使用空格,有助于提高可读性。系统会忽略行开头和结尾的空格。若要添加注释,请在注释前面加上 # 字符。请注意,# 字符后面的所有内容都会被忽略。常见格式为 <field>:<value><#optional-comment>。
Google 支持以下字段:
user-agent:标识相应规则适用于哪些抓取工具。
allow:可抓取的网址路径。
disallow:不可抓取的网址路径。
sitemap:站点地图的完整网址。
allow 和 disallow 字段也称为指令。这些指令始终以 directive: [path] 的形式指定,其中 [path] 可以选择性使用。默认情况下,指定的抓取工具没有抓取限制。抓取工具会忽略不带 [path] 的指令。
如果指定了 [path] 值,该路径值就是 robots.txt 文件所在网站的根目录的相对路径(使用相同的协议、端口号、主机和域名)。路径值必须以 / 开头来表示根目录,该值区分大小写。详细了解基于路径值的网址匹配。
user-agent
user-agent 行用来标识相应规则适用于哪些抓取工具。请参阅 Google 抓取工具和用户代理字符串,获取可在 robots.txt 文件中使用的用户代理字符串的完整列表。
user-agent 行的值不区分大小写。
disallow
disallow 指令用来指定不能被 disallow 指令所属的用户代理行所标识的抓取工具访问的路径。抓取工具会忽略不含路径的指令。
Google 无法将禁止抓取的网页的内容编入索引,但可能仍会将其网址编入索引并将其显示在搜索结果中,但不显示摘要。了解如何阻止编入索引。
disallow 指令的值区分大小写。
用法:
disallow: [path]
allow
allow 指令用来指定相应抓取工具可以访问的路径。如果未指定路径,该指令将被忽略。
allow 指令的值区分大小写。
用法:
allow: [path]
sitemap
根据 sitemaps.org 规定,Google、Bing 和其他主流搜索引擎支持 robots.txt 中的 sitemap 字段。
sitemap 字段的值区分大小写。
用法:
sitemap: [absoluteURL]
[absoluteURL] 行指向站点地图或站点地图索引文件的位置。 此网址必须是完全限定网址,包含协议和主机,且无需进行网址编码。此网址不需要与 robots.txt 文件位于同一主机上。您可以指定多个 sitemap 字段。sitemap 字段不依赖于任何特定的用户代理,只要未被禁止抓取,所有抓取工具都可以追踪它们。
例如:
user-agent: otherbot
disallow: /kale
sitemap: https://example.com/sitemap.xml
sitemap: https://CDN.example.org/other-sitemap.xml
sitemap: https://ja.example.org/テスト-サイトマップ.xml
行和规则分组
通过对每个抓取工具重复 user-agent 行,可将适用于多个用户代理的规则组合在一起。
例如:
user-agent: a
disallow: /c
user-agent: b
disallow: /d
user-agent: e
user-agent: f
disallow: /g
user-agent: h
此示例中有四个不同的规则组:
用户代理"a"为一组
用户代理"b"为一组
用户代理"e"和"f"为一组
用户代理"h"为一组
有关组的技术说明,请参阅 REP 的第 2.1 节。
用户代理的优先顺序
对于某个抓取工具而言,只有一个组是有效的。Google 抓取工具会在 robots.txt 文件中查找包含与抓取工具的用户代理相匹配的最具体用户代理的组,从而确定正确的规则组。其他组会被忽略。所有非匹配文本都会被忽略(例如,googlebot/1.2 和 googlebot* 均等同于 googlebot)。这与 robots.txt 文件中的组顺序无关。
如果为用户代理声明多个特定组,则这些组中适用于该特定用户代理的所有规则会在内部合并成一个组。 特定于用户代理的组和全局组 (*) 不会合并。
示例
user-agent 字段的匹配情况
user-agent: googlebot-news
(group 1)
user-agent: *
(group 2)
user-agent: googlebot
(group 3)
以下为抓取工具选择相关组的方法:
每个抓取工具追踪的组 Googlebot News googlebot-news 遵循组 1,因为组 1 是最具体的组。 Googlebot(网络) googlebot 遵循组 3。 Googlebot Images googlebot-images 遵循组 2,因为没有具体的 googlebot-images 组。 Googlebot News(抓取图片时) 抓取图片时,googlebot-news 遵循组 1。 googlebot-news 不会为 Google 图片抓取图片,因此它只遵循组 1。 Otherbot(网络) 其他 Google 抓取工具遵循组 2。 Otherbot(新闻) 抓取新闻内容但未标识为 googlebot-news 的其他 Google 抓取工具遵循组 2。即使有相关抓取工具的对应条目,也只有在明确匹配时才会有效。规则分组
如果 robots.txt 文件中有多个组与特定用户代理相关,则 Google 抓取工具会在内部合并这些组。例如:
user-agent: googlebot-news
disallow: /fish
user-agent: *
disallow: /carrots
user-agent: googlebot-news
disallow: /shrimp
抓取工具会根据用户代理在内部对规则进行分组,例如:
user-agent: googlebot-news
disallow: /fish
disallow: /shrimp
user-agent: *
disallow: /carrots
allow、disallow 和 user-agent 以外的其他规则会被 robots.txt 解析器忽略。这意味着以下 robots.txt 代码段被视为一个组,因此 user-agent a 和 b 均受 disallow: / 规则的影响:
user-agent: a
sitemap: https://example.com/sitemap.xml
user-agent: b
disallow: /
当抓取工具处理 robots.txt 规则时,会忽略 sitemap 行。 例如,下面说明了抓取工具如何理解之前的 robots.txt 代码段:
user-agent: a
user-agent: b
disallow: /
基于路径值的网址匹配
Google 会以 allow 和 disallow 指令中的路径值为基础,确定某项规则是否适用于网站上的特定网址。为此,系统会将相应规则与抓取工具尝试抓取的网址的路径部分进行比较。 路径中的非 7 位 ASCII 字符可以按照 RFC 3986 作为 UTF-8 字符或百分号转义的 UTF-8 编码字符纳入。
对于路径值,Google、Bing 和其他主流搜索引擎支持有限形式的通配符。这些通配符包括:
* 表示出现 0 次或多次的任何有效字符。
$ 表示网址结束。
路径匹配示例 / 匹配根目录以及任何下级网址。 /* 等同于 /。结尾的通配符会被忽略。 /$ 仅匹配根目录。任何更低级别的网址均可抓取。 /fish 匹配以 /fish 开头的任何路径。匹配项:
/fish
/fish.html
/fish/salmon.html
/fishheads
/fishheads/yummy.html
/fish.php?id=anything
不匹配项:
/Fish.asp
/catfish
/?id=fish
/desert/fish
注意:匹配时区分大小写。 /fish* 等同于 /fish。结尾的通配符会被忽略。
匹配项:
/fish
/fish.html
/fish/salmon.html
/fishheads
/fishheads/yummy.html
/fish.php?id=anything
不匹配项:
/Fish.asp
/catfish
/?id=fish /fish/ 匹配 /fish/ 文件夹中的任何内容。
匹配项:
/fish/
/animals/fish/
/fish/?id=anything
/fish/salmon.htm
不匹配项:
/fish
/fish.html
/Fish/Salmon.asp /*.php 匹配包含 .php 的任何路径。
匹配项:
/index.php
/filename.php
/folder/filename.php
/folder/filename.php?parameters
/folder/any.php.file.html
/filename.php/
不匹配项:
/(即使其映射到 /index.php)
/windows.PHP /*.php$ 匹配以 .php 结尾的任何路径。
匹配项:
/filename.php
/folder/filename.php
不匹配项:
/filename.php?parameters
/filename.php/
/filename.php5
/windows.PHP /fish*.php 匹配包含 /fish 和 .php(按此顺序)的任何路径。
匹配项:
/fish.php
/fishheads/catfish.php?parameters
不匹配项: /Fish.PHP
规则的优先顺序
匹配 robots.txt 规则与网址时,抓取工具会根据规则路径的长度使用最具体的规则。如果规则(包括使用通配符的规则)存在冲突,Google 将使用限制性最弱的规则。
以下示例演示了 Google 抓取工具会对特定网址应用什么规则。
示例情况 http://example.com/page allow: /pdisallow: /
适用规则:allow: /p,因为它更具体。 http://example.com/folder/page allow: /folder
disallow: /folder
适用规则:allow: /folder,因为存在多个匹配规则时,Google 会使用限制性最弱的规则。 http://example.com/page.htm allow: /page
disallow: /*.htm
适用规则:disallow: /*.htm,因为它与网址中的字符匹配得更多,因此更具体。 http://example.com/page.php5 allow: /page
disallow: /*.ph
适用规则:allow: /page,因为存在多个匹配规则时,Google 会使用限制性最弱的规则。 http://example.com/ allow: /$
disallow: /
适用规则:allow: /$,因为它更具体。 http://example.com/page.htm allow: /$
disallow: /
适用规则:disallow: /,因为 allow 规则仅适用于根网址。
TAG:谷歌object detection
SEO就是搜索引擎优化:让你的网站在搜索引擎(比如百度、谷歌)的排名更靠前,当用户通过关键词搜索时更容易搜到你的网站,从而实现企业品牌曝光、主动获客和营销推广的目标。为什么要做SEO?
提高网站访问量:SEO能让你的网站在搜索引擎结果中更靠前,吸引更多客户点击。
降低市场营销成本:相比于付费广告,SEO是一种更经济有效的营销方式。
提升品牌知名度:网站排名靠前,可以让更多用户看到你的品牌名称和信息,增强品牌影响力。
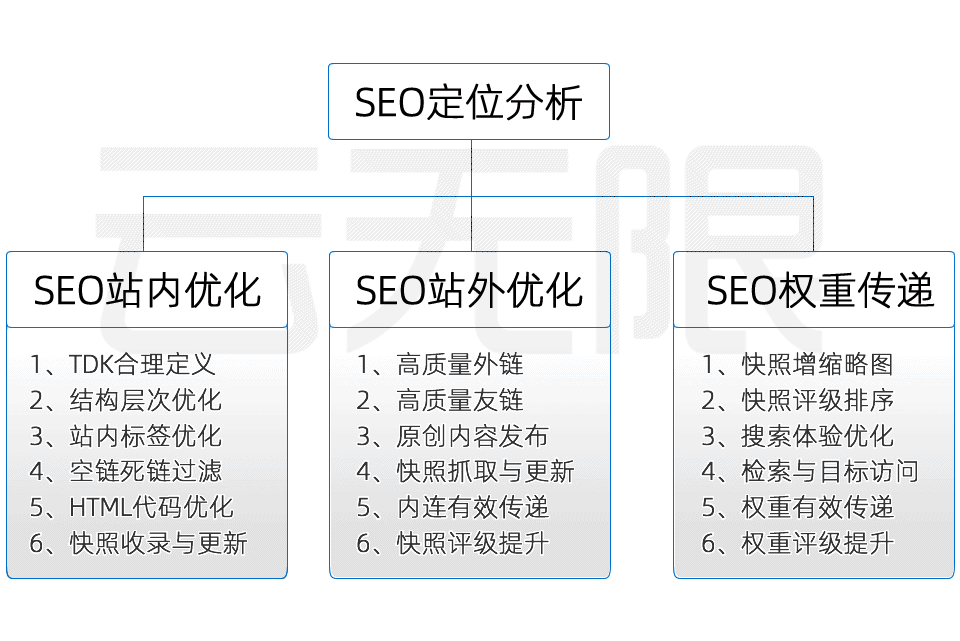 SEO优化有哪些优势?
SEO优化有哪些优势?成本低廉:主要成本是优化师的工资。
效果稳定:一旦网站排名上升,效果稳定持久,可持续获得展现机会。
不受地域限制:SEO的效果可以覆盖全球,不受时间和空间的限制。
什么样的公司更适合做SEO优化呢?大多数行业都可以从SEO中受益。特别是那些希望用户主动访问我们的网站、降低营销成本、提升品牌知名度的企业。通过SEO来优化自己的网站,可吸引更多潜在客户。
SEO是一种工人的有效的网络营销手段,可以帮助企业提升关键词排名,吸引更多用户,实现商业目标。SEO是一个长期且专业的技术,企业在进行SEO时,必须耐心优化,因为SEO涉及到的不止是网站结构、内容质量、用户体验、外部链接这几个方面;还有算法的更替、蜘蛛的引导、快照的更新、参与排序的权重等。

SEO策略


搜到你
让用户搜到你的网站是做SEO优化的目标,拥有精湛的SEO技术、丰富的经验技巧以及对SEO规则的深刻把握才有机会获得更云无限!

了解你
确保网站内容清晰、准确、易于理解,使用户能够轻松找到所需信息.使用简洁明了的标题和描述,帮助用户快速了解你的产品服务!

信任你
将企业的核心价值、差异化卖点、吸引眼球的宣传语等品牌词尽可能多的占位搜索前几页,增强用户印象,优化用户体验让访客信任你!

选择你
优化落地页引导用户咨询或预约留言,引用大型案例或权威报道彰显品牌实力,关注用户需求和反馈,不断优化产品服务让用户选择你!
关键词研究

品牌关键词
提升品牌知名度、塑造品牌形象,吸引对品牌感兴趣的用户,同时帮助监测品牌在搜索引擎中的表现。

核心关键词
是网站内容的主要焦点,能吸引大量目标受众,提高网站在相关搜索中的排名。搜索量大,竞争较激烈。

长尾关键词
更能够更精确地定位目标受众,提高转化率,竞争相对较小更容易获得排名,更符合用户的具体搜索意图。

区域关键词
针对特定地区进行优化,帮助本地企业吸引当地用户,提高本地市场的曝光度。适用于有地域性需求的企业。


竞品关键词
与竞争对手品牌或产品相关的词,通过分析这些关键词,可以了解竞争对手的优势和劣势。

产品关键词
直接针对产品进行优化,与具体产品或服务直接相关,如产品名称、型号、功能等描述性词汇。

搜索下拉词
反映用户的搜索习惯和需求,是搜索引擎根据用户输入自动推荐的词汇,与用户搜索意图高度相关。

相关搜索词
提供与主题相关的其他搜索词汇,帮助用户发现更多相关内容,同时扩展网站的优化范围。
站内SEO

TDK优化
力争一次性完成网站页面标题、描述、关键词的的合理部署

链接优化
包含LOGO链接、导航链接、文章链接及外部链接等SEO优化设置

HTML优化
HTML代码、标签等优化:H,alt,strong,title,span,title等标签

内容优化
固定内容与关键词SEO匹配、动态内容提升蜘蛛抓取率增强快照评级
站外SEO

1)降低文章内容在搜索结果的重合度。尤其是文章标题、段落主题、内容摘要等;
2)标题包含关键词(可包含部分或完整匹配)字数控制在24字内;
3)提炼的文章概要(100字内)必须与关键词有相关性才有意义;
4)新文章不要增加锚文本超链接,等文章快照有排名后再扩充锚文本链接;
5)文章内容与标题关键词相呼应,建立关联,也可根据关键词扩充有关的内容;
6)文章中的图片最好增加alt属性,图片不要失真和变形,宽度大于500px更优机会抢占搜索快照缩略图;
7)文章排版合理、段落分明、段落主题用H标签加强,段落内容用span或p标签区分;
8)发布文章后先引导收录。如提交搜索引擎登录、合理使用有排名快照的内部链接;
9)如果文章7天还没有收录,就要提升文章内容质量再发布;


